Jaguar: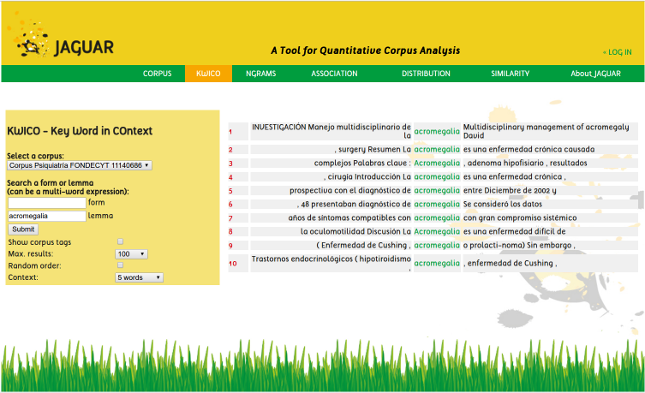
Jaguar is a tool for corpus exploitation. This software can analyze textual corpora from a user or from the web and it is currently available as a web application as well as a Perl module. The functions that are available at this moment are: vocabulary analysis of corpora, concordance extractions, n-gram sorting and measures of association, distribution and similarity.
Jaguar is essentially a Perl module instantiated as a web application. A web application has the advantage of being executable in any platform without installation procedures. However, with the module users are capable of building their own sequence of procedures, taking the output of a process to be the input of another process. The web interface has the limitation that only one procedure can be executed at a time, meaning that the output of a process has to be manually fed as input for the next process.
The project is a full renovation and extension of the old "Jaguar Project" carried out at Universitat Pompeu Fabra in Barcelona from 2006 to 2012. The title of the current project is: "Jaguar: an open-source prototype for quantitative corpus analysis" The results of this project will be officialy presented in January 2017 at the university headquarters, in Av. Brasil #2950, Valparaíso, Chile. We are also planning to offer an introductory Workshop on the use of this tool in the summer of 2017, maybe in Valparaíso, maybe in Santiago, or maybe in both places. Drop a line if interested.
|
 » The universe is not perfect, but it's working on it.
ABOUT
RESEARCH
SOLUTIONS
SOFTWARE
CONTACT
» The universe is not perfect, but it's working on it.
ABOUT
RESEARCH
SOLUTIONS
SOFTWARE
CONTACT
|
Technologies for Linguistic Analysis |
||