
|
Dsele Dismark Estilector GeNom Jaguar Kind Kwico Neven POL Poppins Porcus pullPOS Sapo Sicam Termout Verbario |
Bifid: Parallel corpus alignment at the document, sentence and vocabulary levels
Bifid is a program for parallel corpora alignment:
July 29, 2024: We updated the server and everything looks fineLast week we did some long awaited maintenance service of the hardware hosting this website. Everything went smoothly and we haven't encountered any bugs so far. Anyway, if you happen to see something off, please drop a line to rogelio dot nazar at pucv dot cl. Cheers!Bifid is a program that takes a set of documents with their translations and performs different functions:
Give it a try: Here you have a nice little parallel corpus in English and Spanish extracted from Revista Chilena de Neuropsiquiatría. Download the zip file and upload it again to your account. You can also upload a tmx file if you have it already, and in this way bypass the document and sentence alignment. Here is an example file from Opus corpus: emea.tmx.zip (warning: this is a large file and it takes time to process). Lastly, if you want to try with a different pair of languages, here is subset of the Canadian Hansards, with English and French. Bifid has been online in one way or another since 2004 (yes, it's going to be 20 years now). Lately, its server had gone down and it was neglected. But here it is, again, restored to its former glory. Some (old) publications on the project: Nazar, R. (2011). Parallel corpus alignment at the document, sentence and vocabulary levels. Procesamiento del Lenguaje Natural, n. 47. Nazar, R. (2012). Bifid: un alineador de corpus paralelo a nivel de documento, oración y vocabulario. Linguamatica, vol. 4, no. 2. If you have questions, feel free to send email: rogelio dot nazar at pucv dot cl Error while reading file. References: Nazar, R. (2011). "Parallel corpus alignment at the document, sentence and vocabulary levels". Procesamiento del Lenguaje Natural, n. 47. Nazar, R. (2012). "Bifid: un alineador de corpus paralelo a nivel de documento, oración y vocabulario". Linguamatica, vol. 4, no. 2. Contact: rogelio.nazar at gmail.com Related concepts: Parallel Corpus Alignment, Bilingual Vocabulary Extraction, Machine Translation, Computational Linguistics, Computational Lexicography |
DSELE: a dictionary of Spanish verbs with 'se'
|
Estilector:
This proposal is aimed at improving academic writing skills of students through the creation, development and implementation of a web tool that assists in detecting these problems of style that can be found in drafting academic work. It offers additional explanations, bibliographic support and online resources. The tool is not intended to correct grammatical or spelling errors, but those problems such as repeating words close in the text, poor vocabulary, the use of colloquialisms, the unequal structure of paragraphs, and so on. All these issues cannot be detected by programs such as Word, and yet they are critical to academic achievement. Our proposal is not to create a merely "corrector", but a teaching tool that fosters independent learning because the student can work on these aspects independently of the work of the classroom, albeit also complementary. The idea is that the tool will help students improve their writing during the process of performing the task. In addition, the program also encourages autonomy in the sense that it suggests solutions to the student, but does not correct the text, so that it is the student who ultimately decides whether or not the suggested changes apply.
|
GeNom:
GeNom: automatic detection of the gender of proper names is a project we have been granted on June 20, 2017, funded by the Technology Prototypes track of the Innovation and Entrepreneurship 2017 Competition (Vicerrectoría de Investigación y Estudios Avanzados - Pontificia Universidad Católica de Valparaíso). The result is offered as a web service for batch processing of information for terminography or lexicography projects or for mailing purposes. Abstract: This software is designed to automatically determine the gender of a list of names based on their co-occurrence with words and abbreviations in a large corpus. GeNom is different from other forms of automatic name gender recognition software because it is based on natural language processing and does not rely on already compiled lists of first names, systems that get quickly outdated and cannot analyze previously unseen names. GeNom uses corpora to address the problem, because it offers the possibility of obtaining real and up-to-date name-gender links and performs better than machine learning methods: 93% precision and 88% recall on a database of ca. 10,000 mixed names. This software can be used to conduct large scale studies about gender, as gender bias for example, or for a variety of other NLP tasks, such as information extraction, machine translation, anaphora resolution and others. It is designed to work with Spanish names, as it works with a Spanish corpus, but it will be able to process names in other languages as well, provided that they use the same alphabet. Web demo: http://www.tecling.com/genom
|
Jaguar: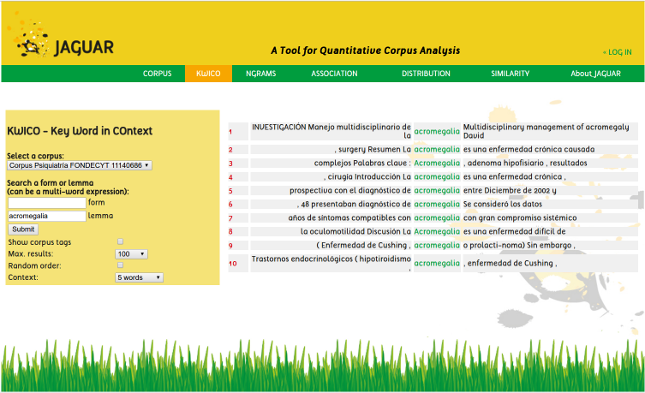
Jaguar is a tool for corpus exploitation. This software can analyze textual corpora from a user or from the web and it is currently available as a web application as well as a Perl module. The functions that are available at this moment are: vocabulary analysis of corpora, concordance extractions, n-gram sorting and measures of association, distribution and similarity.
Jaguar is essentially a Perl module instantiated as a web application. A web application has the advantage of being executable in any platform without installation procedures. However, with the module users are capable of building their own sequence of procedures, taking the output of a process to be the input of another process. The web interface has the limitation that only one procedure can be executed at a time, meaning that the output of a process has to be manually fed as input for the next process.
The project is a full renovation and extension of the old "Jaguar Project" carried out at Universitat Pompeu Fabra in Barcelona from 2006 to 2012. The title of the current project is: "Jaguar: an open-source prototype for quantitative corpus analysis" The results of this project will be officialy presented in January 2017 at the university headquarters, in Av. Brasil #2950, Valparaíso, Chile. We are also planning to offer an introductory Workshop on the use of this tool in the summer of 2017, maybe in Valparaíso, maybe in Santiago, or maybe in both places. Drop a line if interested.
|
KIND (aka The Taxonomy Project)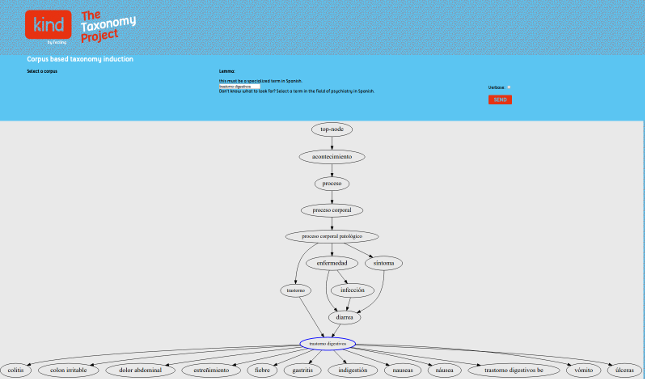
We designed a statistically-based
taxonomy induction algorithm consisting of a combination of different strategies not involving explicit linguistic knowledge. Being all
quantitative, the strategies we present are however of different nature. Some of them are based on the computation of distributional
similarity coefficients which identify pairs of sibling words or co-hyponyms, while others are based on asymmetric co-occurrence and
identify pairs of parent-child words or hypernym-hyponym relations. A decision making process is then applied to combine the results
of the previous steps, and finally connect lexical units to a basic structure containing the most general categories of the language. We
evaluate the quality of the taxonomy both manually and also using Spanish Wordnet as a gold-standard. We estimate an average of
89.07% precision and 25.49% recall considering only the results which the algorithm presents with high degree of certainty, or 77.86%
precision and 33.72% recall considering all results.
+ Nazar, R.; Balvet, A.; Ferraro, G.; Marín, R.; Renau, I. (2020). "Pruning and repopulating a lexical taxonomy: experiments in Spanish, English and French". Journal of Intelligent Systems, vol. 30 num. 1, pp. 376-394.
|
KWiCo:This project is part (or a "spin-off") of the Perl module Jaguar, which is currently ongoing with funding from the Innovation and Entrepeneurship 2016 Program of Pontificia Universidad Católica de Valparaíso, within the "Technological Prototyes" track. KWiCo is a corpus indexing algorithm. It takes a corpus as input and produces a table with an index of the corpus, thus significantly reducing the time needed to retrieve concordances, especially when the corpus is very large.
|
NEVEN
We present a study in the field of the automatic
detection of non-deverbal eventive nouns, which
are those nouns that designate events but have not
experienced a process of derivation from verbs, such
as fiesta (‘party’) or cóctel (‘cocktail’) and, for this
reason, do not present the typical morphological features
of deverbal nouns, such as -ci´on, -miento, and
are therefore more difficult to detect.
In the present research we continue and extend the
work initiated by Resnik
(2010), who offers a number
of cues for the detection of this type of lexical unit. We
apply Resnik’s ideas and we also add new ones, among
them, the inductive analysis of the words that tend to
co-occur with eventive nouns in corpora, in order to
use them as predictors of this condition. Furthermore,
we simplify the classification algorithm considerably,
and we apply the experiments to a larger corpus, the
EsTenTen (Kilgarriff & Renau, 2013), comprising more
than 9 billion running words. Finally, we present
the first results of the automatic extraction of eventive
nouns from the corpus, among which we find plenty
non-deverbal nouns.
perl neven.pl input.txt > result.htm
|
POL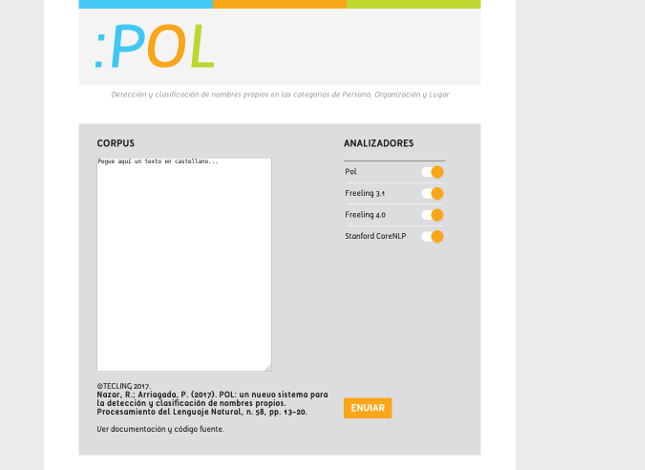
The purpose of this research is to develop a methodology for the detection
and categorisation of named entities or proper names (PPNN), in the categories of
geographical place, person and organisation. The hypothesis is that the context of
occurrence of the entity –a context window of n words before the target– as well as
the components of the PN itself may provide good estimators of the type of PN. To
that end, we developed a supervised categorisation algorithm, with a training phase
in which the system receives a corpus already annotated by another NERC system.
In the case of these experiments, such system was the open-source suite of language
analysers FreeLing, annotating the corpus of the Spanish Wikipedia. During this
training phase, the system learns to associate the category of entity with words of
the context as well as those from the PN itself. We evaluate results with the CONLL-
2002 and also with a corpus of geopolitics from the journal Le Monde Diplomatique
in its Spanish edition, and compare the results with some well-known NERC systems
for Spanish.
To train POL for making a new model, you need to have Perl's Storable module installed.
These models were created
with a x86_64 HP Proliant machine with GenuineIntel CPU 1064.000 MHz running Linux (Ubuntu 14.04). If you have a different kind of machine (e.g., a Desktop pc on Windows), then you will probably need to create the models again by using poltrain.pl.
|
Poppins:
Poppins a very simple and yet effective algorithm for document categorization.
Text categorization has became a very popular
issue in computational linguistics and it has developed to great complexity, motivating a large
amount of literature.
Document categorization can be used in many scenarios. For instance,
an experiment on authorship attribution can be seen as a text categorization problem.
That is to say, each author represents a category and the
documents are the elements to be classified.
This system can be
used as a general purpose document classifier, for example by content instead of authorship,
because it only reproduces the criterion that it learned during the training phase.
This program is language independent because it uses purely mathematical
knowledge: an n-gram model of texts. It works in a very simple way and is therefore easy to
modify. In spite of its simplicity, this program is capable of classifying documents by author
obtaining more than 90% of accuracy.
|
Termout:
We have a new version of Termout! (July 2nd, 2024) We have a new version of Termout, our terminology extraction system: http://www.tecling.cl/cgi-bin/termout2024 Actually, what we have is more like a preview, as the only part currently available to the public is the terminology extraction part, but that is the most important part of the process. Compared to its predecessor, this new version is blazingly fast, and performance evaluation (soon to be published) shows that it also has better precision and recall. We are working very hard to get the rest of the functions ready and update the documentation. The old version (2023) will continue to exist for a while in the oriniginal URL: http://www.termout.org/ . As soon as we finish the migration, this URL will point to the new version. |
Verbario:
Verbario is our first attempt to extract lexical patterns using corpus statistics. A pattern is a structure that combines syntactic and semantic features and is linked to a conventional meaning of a word. This means, for example, that the verb to die does not have intrinsic meanings, but potential meanings which are activated by the context: in ‘His mother died when he was five’, the meaning of the verb differs from ‘His mother is dying to meet you’, due to collocational restrictions and syntactic differences. With the automatic analysis of thousands of concordances per verb, we can make a first approach to the problem of detecting these structures in corpora, a very time-consuming task for lexicographers. The average precision is around 50%. The next step to increase precision is adding a dependency parser to the system and make adjustments to the automatic taxonomy we have created for semantic labeling.
|