1º de julio, 2026Hernán Robledo presenta seminario en la Universidad Autónoma de Barcelona
|

|
Hoy presentó Hernán Robledo un seminario
en la Facultad de Filosofía y Letras de la Universidad Autónoma de Barcelona,
en el que expuso resultados preliminares de su proyecto de Investigación Fondecyt
en curso.
El proyecto aborda el estudio de la variación en el uso de marcadores discursivos
de los géneros digitales, particularmente en redes sociales como Twitter y YouTube,
y más concretamente en los comentarios que realizan los usuarios sobre los contenidos y
sobre los comentarios de otros usuarios.
A diferencia del texto escrito para ser impreso, el texto de las redes sociales
presenta mayor volatilidad y creatividad, alejándose considerablemente de la norma
escrita y formal. Esto
promueve el uso de formas no inventariadas y de expresiones en distintas etapas del proceso de fijación.
Por medio de una metodología mixta de análisis de corpus, con medios tanto cualitativos
como computacionales, el proyecto se dedica a cartografiar esta terra incognita.
|
22 de junio, 2026Ignacio Lobos defiende su tesis doctoral
|
Hoy Ignacio Lobos defendió su tesis doctoral en la Pontificia Universidad Católica de Valparaíso, titulada ``Marcadores discursivos en el género Tesis y su distribución según movidas retóricas, nivel de inserción y disciplina'', dirigida por Irene Renau y Rogelio Nazar.
En su trabajo, Ignacio aborda el estudio descriptivo de los marcadores discursivos (MD) en la producción textual académica, en particular en el género tesis, hecho fundamental en la formación universitaria. La contribución de la tesis es la vinculación de los MD con tres variables: las llamadas `movidas retóricas', la variedad disciplinar y el nivel de inserción académica del estudiante. Se trata de un estudio basado en los métodos de la lingüística de corpus, y se constituyó un corpus específico para la investigación, denominado TELIDOC 2022, que recopila tesis de licenciatura y doctorado en tres disciplinas (lingüística, derecho y acuicultura).
El objetivo principal es identificar la distribución de los MD considerando estas tres
variables, y sus resultados son un aporte tanto teórico como práctico. Teóricamente ofrece un entendimiento más profundo de las propiedades lingüísticas de los MD en el género tesis. En lo práctico, los resultados servirán para el desarrollo de nuevas herramientas de enseñanza de la escritura académica,
guiando a los tesistas sobre las funciones discursivas más adecuadas según su disciplina y nivel
de avance académico.
Desde aquí enviamos nuestras felicitaciones a Ignacio.
Es un orgullo haber colaborado con él.
|

|
June 15, 2026New paper at the International Journal of Lexicography
|

|
We have a new paper published at the IJL:
Nazar, Rogelio (2026). Semantic Typing for Corpus Pattern Analysis. International Journal of Lexicography, Volume 39, 2026, ecag012, https://doi.org/10.1093/ijl/ecag012
Abstract
For the ongoing creation of a database of Spanish verbs, we developed a methodological proposal for the automatic tagging of semantic types in running text according to Hanks’ Corpus Pattern Analysis (CPA) guidelines. In this task, a text document is the input and the output is the tagging of each noun, noun phrase or proper noun with one of the semantic types in the CPA Ontology. The present proposal is based on a combination of algorithms for automatic ontology population, named entity recognition and, most importantly, word sense disambiguation, to assign the appropriate type to a noun according to the context. The paper includes an evaluation of the method tagging a random sample of 200 Wikipedia pages in Spanish and English. Evaluation figures by a panel of three experts show 84% precision and 88% recall in Spanish and 83% precision and 93% recall in English. These are competitive results considering the simplicity and computational efficiency of the algorithm.
. |
4 de junio de 2026Presentamos en el XI Congreso Internacional de Lexicografía Hispánica
|
Irene Renau, Rogelio Nazar y Hernán Robledo presentaron el trabajo titulado “Diccionarios sostenibles: la estadística de corpus integrada en un proyecto de diccionario multilingüe de marcadores discursivos” en el XI Congreso Internacional de Lexicografía Hispánica, que tuvo lugar en la Universidad de Cádiz.
Resumen de la presentación
En esta propuesta presentamos un proyecto en curso de diccionario multilingüe en línea de
marcadores discursivos. El diccionario parte de un proyecto previo de extracción
automatizada de marcadores discursivos en corpus (Nazar, 2021; Nazar, Renau y Robledo,
2024). En dicho proyecto, se diseñó e implementó un método para la identificación de estas
unidades discursivas en un corpus paralelo (Opus Corpus) que alinea textos del alemán,
catalán, español, francés e inglés, y permite clasificar los marcadores utilizando una
taxonomía
existente
(Martín
Zorraquino
y
Portolés,
1999). El sistema, puramente
estadístico y con una alta precisión, tiene la ventaja de ofrecer datos procedentes de
condiciones naturales de uso de estas unidades, sistematizados de forma coherente y en
grandes cantidades; por ello, aunque requiere la revisión y limpieza posteriores por parte de
un experto, se trata de una opción metodológica que vale la pena valorar para la creación de
un diccionario.
El diccionario que se presenta es multilingüe unidireccional (es decir, contiene
artículos en español con equivalencias en los ya mencionados idiomas) y dispone, por
ahora, de una microestructura con lema, variantes del lema, categoría de marcador, registro,
función o funciones, ejemplos de corpus, aspectos normativos (ej., puntuación) y
equivalentes en inglés y otras lenguas. En esta comunicación nos
centraremos en la descripción del método de trabajo, especialmente en la articulación entre
el trabajo computacional y el lexicográfico, dada la acuciante necesidad en lexicografía de
ofrecer alternativas a los métodos tradicionales, que son poco sostenibles económicamente,
requieren equipos grandes y son muy lentos; presentaremos también una primera muestra
de artículos asociados a una de las categorías de marcadores.
Referencias
Martín Zorraquino, M. A. y Portolés, J. (1999). Los marcadores del discurso. En I. Bosque y
V. Demonte (Eds.), Gramática descriptiva de la lengua española (Vol. 3, pp. 4051-4214).
Espasa.
Nazar, R. (2021). Inducción automática de una taxonomía multilingüe de marcadores
discursivos: primeros resultados en castellano, inglés, francés, alemán y catalán.
Procesamiento del Lenguaje Natural, 67, 127-138.
Nazar, R.; Renau, I.; Robledo, H. (2024). Dismark and Text·a·Gram: Automatic
identification and categorization of discourse markers in texts. En C. M. Popescu y
O. A. Dut,ă (Eds.), Discourse Markers in Romance Languages. Crosslinguistic Approaches in
Romance and Beyond. Peter Lang.
|

|
April 23, 2026New paper by Ježek & Renau
|

|
Happy Sant Jordi!
Today we have a double celebration because a new paper
has just been published:
Elisabetta Ježek and Irene Renau (2026). A Storm of Ideas: Towards Corpus Pattern Analysis for Nouns. International Journal of Lexicography, Vol. 39, 2026, ecag007, https://doi.org/10.1093/ijl/ecag007.
Abstract
Corpus Pattern Analysis (CPA) is a technique for mapping meaning onto words in text. It was first proposed by Patrick Hanks in 2004 and has since been applied to detect and analyse recurrent syntagmatic patterns centred around verbs across various languages. In this paper, following a suggestion by Hanks himself (Hanks 2004a, 2004b, 2012, 2013), we explore the possibility of applying it to patterns centred around nouns. We conduct an exploratory study of three Spanish nouns with the goal of identifying their most recurrent patterns. Results show that: i. the current CPA apparatus can be successfully used to identify noun patterns, but it requires adjustments and extensions, particularly, the construction of a new ontology for verbs and adjectives; ii. in contrast to verbs, nouns can have more than one pattern per meaning, especially in the case of literal senses, and their meaning may be assigned by collocates that are outside their pattern; iii. metaphorical patterns show more syntactico-semantic restrictions, which may be useful for establishing links between metaphors and language.
. |
April 3, 2026New paper and semantic tagger: the Wicacho Project
|
A new issue (n. 76) of the journal Procesamiento del lenguaje Natural has just been published, and with it, the following paper:
Nazar, R.; Renau, I. (2026). Wikipedia used as a semantic tagger: some preliminary results in Spanish. Procesamiento del Lenguaje Natural, n. 76, p. 279-292.
With that publication we officially inaugurate Wicacho, our new open source project for semantic tagging based on data from Wikipedia:
http://www.tecling.com/wicacho
The project's website offers documentation, data, source code and a web demo. This new tagger will replace (or, rather, integrate) Tatatag, our previous attempt for semantic tagging based on Wiktionary. Tatatag was effective with nous of the general vocabulary, but offered only limited treatment of proper nouns and specialized vocabulary, the domain in which Wicacho excels. |

|
March 25, 2026
|

|
Irene Renau (Universtitat Autònoma de Barcelona) presented a talk in Viña del Mar, Chile, at the Emlex Colloquium: Lexicography, Didactics And Language Technologies of the European Master in Lexicography (EMLex). The event was held this week at the Faculty of Philosophy and Education of the Pontificia Universidad Católica de Valparaíso.
The title of the presentation was “The Dismark project: Integrating corpus statistics, lexicography, and didactics of written communication”. She described a lexicography project aimed at a multilingual dictionary of discourse markers, a work developed in collaboration with Hernán Robledo (Pontificia Universidad Católica de Valparaíso). More details will be available soon. |
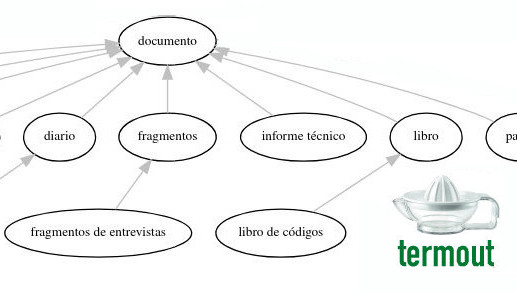
February 9, 2026New version of Termout.org
|
This version of Termout is faster and more accurate: http://termout.org
But... what is Termout, dare you ask?
Termout is a software that helps you develop terminological projects,
and you may be interested if you are a terminologist, translator, interpreter
or if you happen to write or deal with technical papers often.
The basic functions of Termout are:
- to process a specialized corpus in English and Spanish
- extract terms
- classify them in semantic categories
- extract information from the corpus
- extract equivalents in the other language
- obtain synonyms (term variants)
- export-import term databases (CSV, HTML, TBX)
And there is even more!
A recent publication describes some of the new functions:
Nazar, R. (2026). Semi-Automatic Creation of Terminological Databases.
Terminologie & Ontologie :
Théories et Applications. Presses universitaires Savoie Mont Blanc, 117-134
(
PDF
).
|
|
8 de enero, 2026Javier Obreque defiende su Proyecto de Tesis
|

|
Comenzamos el año con una buena noticia: nuestro compañero y colega Javier Obreque, miembro del Grupo Tecling desde
hace ya más de una década, acaba de defender su proyecto de tesis doctoral en el Instituto de Literatura
y Ciencias del Lenguaje de la Pontificia Universidad Católica de Valparaíso.
El título del trabajo es ``Mecanismos lingüísticos de la subjetividad en el discurso científico:
análisis descriptivo desde los resúmenes de proyectos de investigación concursable FONDECYT Regular''.
El proyecto era dirigido inicialmente por Rogelio Nazar, pero desde su renuncia a la PUCV en setiembre de 2025,
la dirección quedó a cargo de los profesores Pascal Matzler y Hernán Robledo.
El proyecto de tesis doctoral de Javier
es una investigación con un diseño cualitativo-cuantitativo que
pretende desentrañar el funcionamiento
de las marcas de subjetividad en el discurso científico, y como tal es una
contribución al modelamiento descriptivo de géneros discursivos.
En contraste con la creencia socialmente compartida de que
el discurso científico, como parte del carácter del
conocimiento científico y sus formas de comunicación, es objetivo y neutro, lo que
se comprueba en realidad es que en la producción científica y académica
se encuentran diversos mecanismos de expresión de la subjetividad, como
la deixis, la modalización y la despersonalización, que cumplen un propósito
metadiscursivo estratégico vinculado con las estructuras argumentativas
que buscan producir un efecto en el lector.
Por ello, el objetivo del estudio es describir, a partir de sus marcas
lingüísticas empíricas, la manifestación de
subjetividad en los resúmenes de propuestas de proyectos de investigación para obtener
financiamiento en concursos públicos y competitivos en Chile, concretamente en los
resúmenes de Proyectos Fondecyt.
Nunca antes se ha intentado un análisis discursivo
de los proyectos Fondecyt, y no hay duda de que los resultados serán de gran relevancia para comprender mejor
tanto la forma en que se financia la investigación en Chile y los mecanismos retóricos asociados,
como el funcionamiento del discurso científico en general. Estaremos por eso muy atentos
cómo se desarrolla este trabajo. Desde aquí, nuestras felicitaciones a Javier!
PIE DE FOTO: Javier aparece en el centro, con su camisa blanca, flanqueado por los miembros
de la comisión evaluadora (Nina Crespo y Daniela Ibarra) y sus profesores guía (Hernán Robledo y
Pascal Matzler, a su izquierda, y Rogelio Nazar, a su derecha, que justo pasaba por ahí).
|
23 de diciembre, 2025Hernán Robledo se adjudica Proyecto Fondecyt
|
Hernán Robledo, miembro de la vieja guardia del Grupo Tecling, acaba de adjudicarse el
Proyecto Fondecyt Iniciación N°11260185, titulado “Conectores y operadores discursivos en español digital: análisis semiautomático de su variación formal y procesos de fijación en redes sociales”.
El proyecto estudiará el uso de conectores y operadores discursivos en interacciones escritas de plataformas como YouTube y Twitter/X, con el objetivo de sistematizar su variación formal y funcional, así como describir procesos de fijación lingüística en curso en el español contemporáneo. Mediante una metodología mixta que combina análisis lingüístico cualitativo y herramientas de procesamiento del lenguaje natural, la investigación permitirá identificar expresiones emergentes, modelar patrones discursivos y desarrollar un repertorio digital anotado de acceso abierto, con proyecciones en el estudio del discurso digital, la enseñanza del español y las tecnologías del lenguaje.
Desde aquí felicitamos a nuestro colega, que continúa con una línea de investigación en marcadores
discursivos que a este grupo siempre ha interesado mucho. |

| |
Server Status
Local time: Sun Aug 2 20:17:15 2026
| Parameter | Value | Comments |
|---|
| Temperature | 34 C |
Bearable |
|---|
| Memory left | 90 % |
Enough |
|---|
| CPU usage | 0.0 % |
Ok |
|---|
| Storage left | 55 % |
Enough |
|---|
Upcoming Events
Very soon! We are about to present the new version of our semantic tagger, Wikacho. Stay tuned!
Tools & demos
We have implemented different types of applications and most of them can be tested online. Take a look.
+ Bifid: a parallel corpus aligner
+ Compare: a simple script to compare two lists of words
+ Cryptoman: a script to generate cryptograms
+ Dismark: a multilingual taxonomy of discourse markers
+ Dsele: a model dictionary for ELE learners
+ Estilector: computer assisted writing for Spanish
+ GeNom: a program to detect the gender of proper nouns
+ Jaguar: a tool for statistic corpus analysis
+ Kind: a lexical taxonomy induction algorithm
+ Kwico: a concordancer for big corpora
+ Lealem: a reading pacer for parallel German-Spanish texts
+ Leafran: a reading pacer for parallel French-Spanish texts
+ Linguini: a language detector
+ Neven: a program to detect eventive nouns
+ POL: named entity recognition and classification
+ Poppins: a supervised text classifier
+ Porcus: an interface for various taggers and parsers for Spanish
+ pullPOS: a project for the detection of plurals in Spanish
+ Punkt: punktuation of discourse markers in Spanish
+ Randall: a list randomizer
+ Readeutsch: a reading pacer for parallel German-English texts
+ Regex: a Perl script for regular expressions
+ Sapo: a program to detect similarities between documents
+ Sicam: a program to analyze Spanish poetry
+ Termout: a terminology extraction system
+ Text·a·gram: a program to analyze Spanish texts
+ Verbario: corpus pattern analysis in Spanish
|
